Меня коробят выражения вроде: «организмы питаются информацией» или же «организм заключает в себе запас информации». Это по меньшей мере неточно. Организмы не содержат информации: они слагаются из более или менее сложных структур, упорядоченных совокупностей элементов. Свою структуру, как бы сложна она ни была, организм создает сам: за счет химической энергии питательных веществ — как животные, и энергии света — как растения.
Но откуда он берет сведения о своей структуре? Вот тут-то термин «информация» становится необходим. Ведь этот термин, который в наше время у всех на языке и слуху, реже на уме,— характеристика не системы (будь то живой организм или ежедневная газета), а сигнала. (спорно. Кл.) :))
Теория информации утверждает, что любой сигнал независимо от его материального воплощения — будь то радиоволны, звуковые волны, слова на бумаге, рисунки на камне или сочетания нуклеотидов в нуклеиновых кислотах — несет определенное количество информации и его можно измерить. Единицы количества информации — биты, один бит информации содержится в ответе на вопрос: «Кто родился: мальчик или девочка?» Несложные расчеты (которые я здесь ради экономии места опускаю) показывают, что в реальных текстах, написанных на русском языке, информационная стоимость каждого знака (включая сюда буквы, знаки препинания и пробелы между словами) приближается к двум битам.
Если теперь вернуться к вопросу: откуда развивающийся организм берет сведения о своей структуре, то ответ однозначен — из своей генетической программы, из ДНК. В ДНК «генетический текст» закодирован четырьмя «буквами» — аденином, гуанином, цитозином и тимином. Каждая из них содержит информации тоже около двух битов.
То есть тексты, написанные русским языком, и
текст нашей генетической программы обладают
примерно равной информационной емкостью. В этот
ряд естественно встает и белковый текст, который
образуется как продукт реализации генетической
информации. Передатчик этой информации —
хромосома, приемник — цитоплазма клетки, в
которой синтезируется белок. А уж от набора
белковых молекул и их количества зависит
дальнейшая судьба клетки и всего организма.
Сейчас и в школе учат, что одна буква белкового
текста — это аминокислота, точнее, один
аминокислотный остаток в полипептидной цепи,
образующей белок. Его информационная емкость все
те же 2 бита.
Сколько же белков может синтезировать наш
организм? Решая эту проблему, исследователи
столкнулись с парадоксом, получившим название «парадокса лишней ДНК» (она же
«эгоистичная», «паразитическая», «избыточная» и
«мусорная»). О ней-то сейчас и пойдет речь.
Мы привыкли считать, что ген — это та
последовательность нуклеотидов в ДНК, которая
кодирует белок. Отсюда стандартное изречение:
один ген — один белок. Сложилось оно в ту пору,
когда по чисто техническим причинам изучение
генетических программ и их перекодировки
началось с самых простых, какие только есть,
организмов, точнее кишечной палочки и
паразитирующих в ней бактериофагов и вируса
табачной мозаики.
Исследование этих объектов вроде бы
подтверждало прежнюю истину («один ген — один
белок»). Правда, нашлись и исключения. Некоторые
белки складывались из нескольких полипептидных
цепей и кодировались соответственно несколькими
генами. Другие гены кодировали не белки, а нужные
для работы клетки нуклеиновые кислоты —
рибосомныеи транспортные РНК. Но это все
считалось мелочью, и до сих пор многие полагают,
что гены — это та ДНК, которая кодирует белки, а
если она их не кодирует, то это не гены. А что же
это тогда? Какую функцию выполняет ДНК, не
находящая отражения в аминокислотных
последовательностях белков?
Пока изучали простейшие объекты, от этой ДНК
можно было отмахнуться. Ведь геномы бактерий и
фагов построены очень экономно. Там
действительно почти каждая нуклеотидная
последовательность находит отражение в
аминокислотной последовательности белка. Более
того, экономия генетического материала у вирусов
доходит до того, что один ген может кодировать
два, а то и три белка (подробнее
см.«Наука и жизнь» № 1, 1988).
Когда же перешли к высшим организмам, то уже
первые исследования показали, что геномы
эукариот, в том числе и человека, построены по
крайней мере на первый взгляд, чрезвычайно
неэкономично. Как говорят, у них низкая плотность
кодирования генетической информации. Образно
выражаясь, геном вируса — речь
спешащего спартанца, геном человека — речь
заикающегося зануды.
Доказать это очень просто. Сколько белков может
синтезировать организм человека? Примерно 50
тысяч (конечно, в самом грубом приближении).
Нуклеотидов в геноме человека 3,2 миллиарда. Зная
молекулярную массу среднего белка, нетрудно
прикинуть, из скольких аминокислотных остатков
он состоит, сколькими кодонами кодируется.
Помножив полученное на 50 тысяч, мы придем к
выводу, что не меньше 95 процентов ДНК
в геноме лишние. Более того, теперь мы уже
точно знаем, что большая часть ДНК в наших
геномах никаких белков не кодирует, с нее не
считывается в обычных условиях информационная
РНК, а если и считывается, то не находит отражения
в аминокислотных последовательностях. Что же
делает эта ДНК, какова ее функция?
Самый неожиданный ответ на этот вопрос девять
лет тому назад одновременно и независимо друг от
друга рискнули дать У. Ф. Дулиттл со своей
сотрудницей К. Сапиенса и классик молекулярной
биологии Ф. Крик с Л. Орджелом.
Какую же гипотезу они предложили? Теперь за ней
устоялось название «гипотезы эгоистичной ДНК».
Суть ее заключается в том, что или вся ДНК, не
кодирующая белок, или ее значительная часть не
имеет смысла. Изменения в ней не затрагивают
строение организма (фонетические признаки), Она
размножается при каждом делении клеток, не
принося организму пользы, но и не причиняя
существенного вреда,— словом, существует сама
для себя, сохраняя свой состав. В геноме это
нахлебник или паразит, умеющий довольствоваться
малым.
Откуда же среди генов берутся такие эгоисты?
Авторы этой концепции исходят из того, что
нуклеотидная последовательность, существующая в
единичном экземпляре, может размножаться,
образуя десятки, сотни, тысячи и миллионы копий.
Этот процесс давно известен, его называют амплификацией (размножением).
Существует и обратный процесс — выпадение из
генома последовательностей, в том числе и лишних,
амплифицированных. Его назвали делецией.
Нетрудно сообразить, что, если скорость
амплификации хоть немного превысит скорость
делеции, геном быстро переполнится копиями
генов, которые для существования организма
попросту не нужны.
Разумеется, это не может длиться бесконечно. Как только геном клетки переполнится
паразитами, их начнет отсеивать отбор.
Правда, сторонники эгоистичной ДНК полагают, что
энергетические расходы клетки на содержание
ненужной ДНК не очень велики, и потому-де для нее
это необременительно.
В этом я сомневаюсь. Энергии на синтез уходит
действительно не так уж много. Но нужен и
строительный материал для нуклеотидов. Для чего
же мы удобряем растения азотом и фосфором? Уже
давно известны не очень хорошо вписывающиеся в
классическую генетику факты, что некоторые
растения, например, махорка, в условиях азотного
и фосфорного голодания резко снижают количество
ДНК на ядро.
Тут вполне уместна такая аналогия: хотя качество
работы нашей полиграфической промышленности
оставляет желать лучшего, мощность ее вполне
достаточна, что бы наделить каждую семью в Союзе
не только последними детективами, но и полным
собранием сочинений Достоевского. Только где
бумагу взять?..
Термин «эгоистичная» ДНК в общем-то не нов,
раньше была в ходу ДНК «избыточная» и «ненужная».
Теперь ее назвали «паразитической» и «мусорной».
Чуть ли не комплиментом звучал термин
«несведущая» ДНК (она же «невежественная»). Так
называли последовательности, которые в принципе
могли выполнять какую-либо функцию независимо от
состава.
Увлекшиеся теоретики не замечали, что грешат
против логики. Они требуют доказательств
функционального значения ДНК, не кодирующей
белок, принимая ее бесполезность как исходное
положение, В результате у многих молекулярных
генетиков сложилось представление о геноме
высших, ядерных организмов — эукариот, на мой
взгляд, довольно дикое. Геном, например, человека
предстает как куча мусора, в которой ползают
паразиты. Это так называемые «прыгающие гены» —
мобильные, подвижные последовательности ДНК —
потомки вирусов. В эту же массу, как жемчужные
зерна в кучу навоза, вкраплены «настоящие» гены,
то есть кодирующие белки и РНК. Как говаривал
Друг Винни-Пуха ослик Иа-Иа, «душераздирающее
зрелище»! Геном бактерии построен куда
рациональнее. Что же тогда прогресс? Моя точка
зрения на эту проблему проста; с получением новых
экспериментальных данных термин «мусорная»
будет применяться не к ДНК, а к той литературе,
где он всерьез употребляется. Это я говорил еще в
1980 году, прочитав статьи У. Дулиттла и Ф. Крика,
говорю и сейчас — с гораздо большей
убежденностью, основанной на многочисленных уже
новых данных.
А тогда единственным моим доводом была аналогия
с передачей лингвистической информации, и
ссылаться приходилось только на самые общие
положения теории информации. Дело в том, что в
любом канале передачи информации существуют
помехи. Канал без помех — такая же
невозможная абстракция, как и двигатель со
100-процентным КПД. Поэтому сигнал на пути от
передатчика к приемнику искажается — порой
настолько, что не может быть использован в
практической деятельности. Информация, в общем,
просто теряется, обращаясь в шум. Чтобы
сохранить информацию в сигнале, необходимо,
чтобы он был устойчив к помехам.
И теория связи, придуманная людьми, и
закономерности, по которым формирует свои
сигналы живая природа, предусматривают немало
способов повышения помехоустойчивости каналов
связи. Все их нельзя рассмотреть в общедоступном
издании. Но важно подчеркнуть одно: все они в той
или иной мере сводятся к удлинению
сигнала; к увеличению времени
его передачи — словом, к понижению
плотности кодирования генетической
информации. К чему это сводится на практике?
Полагаю, в детстве все читали захватывающую
книгу Жюля Верна, которая начиналась с того, что в
брюхе акулы была найдена бутылка, а в той бутылке
— три записки, Море смыло часть текста, но можно
было догадаться, что они написаны на разных
языках — английском, немецком и французском.
Сопоставив остатки текстов, герои романа «Дети
капитана Гранта» узнали о потерпевших
кораблекрушение, отправились их искать и, в конце
концов, нашли.
Чем для нас примечательна эта выдуманная
история? Прежде всего тем, что текст повторен
трижды, и это подняло его устойчивость к помехам.
Будь копии одноязычными, результат был бы тот же.
Примечательно, что, восстанавливая размытый
текст, Паганель споткнулся на одном только слове
«Табор» (название острова) — оно имелось только
во французском тексте и, значит, не обладало
трехкратной избыточностью. Впрочем, будь оно
расшифровано, героям романа не пришлось бы
совершать кругосветное плавание, и роман вообще
бы не состоялся.
Сопоставим это с тем фактом, что каждый из нас
имеет двойной, диплоидный набор генов — от отца и
от матери. Как говорят генетики, наши
организмы на всем протяжении жизни, начиная с
оплодотворенной яйцеклетки (зиготы), находятся в
диплофазе. Только наши гаметы — спермии и
яйцеклетки — гаплоидны, то есть имеют один набор
генов.
Но это не общий для всей природы закон. Высшие растения имеют стадии развития —
гаплофазу и диплофазу, А многие простейшие, грибы
и водоросли на протяжении большей части жизни
живут в гаплофазе — у них диплоидна только
зигота. Гаплоидны и бактерии.
Какой вывод можно сделать из этого? По-видимому,
дублирование, а то и многократное повторение
генетической информации, необходимо для
прогрессивной эволюции. И необходимо именно
потому, что повышает помехоустойчивость.
Далее. Возьмите русский перевод записки Гранта. В
нем 48 слов, но давайте задумаемся: очень ли важны
для понимания смысла такие слова, как
«трехмачтовое судно», «в тысяче пятистах лье от
Патагонии», «в южном полушарии», «постоянно
терпя жестокие лишения», «здесь они бросили этот
документ»?.. Как будто бы без них можно обойтись.
Получается, что многие слова в тексте письма
лишние?
Да, лишние. А значит, следуя логике авторов модной
гипотезы, их бы следовало назвать
«эгоистическими», ипаразитическими»,
«мусорными» и т. д. Но будет ли это верно? Вы
скажете, конечно, что здесь что-то не так.
Вот мы и подошли к важному выводу о теории
информации; все человеческие и языки построены
со значительной избыточностью. Как оценить
степень этой избыточности? Абсолютно точное
определение этой величины нереально хотя бы
потому, что избыточность — свойство не языка, а
написанного на нем текста. Но сопоставив много
разных текстов, мы можем вывести нечто среднее,
характеризующее язык (что-то вроде средней
температуры по и больнице). Метод определения
доступен каждому. Его можно назвать хотя бы
методом Паганеля, поскольку суть его —
моделирование письма капитана Гранта, В такую
игру удобнее играть вдвоем. Один, по возможности
случайно, выбирает куски текста, неизвестного
партнеру. Достаточно примерно тысячи знаков.
Затем, пользуясь таблицей случайных чисел, из
него вычеркивают 10, 20, 50 или больше процентов
знаков. Второй игрок должен текст восстановить.
Так определяется избыточность текста,
выражающаяся в проценте «лишних» знаков, без
которых задачу можно решить. Хорошо
для этой цели использовать персональный
компьютер.
Подобные опыты, проведенные в разных странах, на
разноязычных текстах, дают близкие цифры:
примерно до 80 процентов знаков в
лингвистической информации оказываются лишними.
Мы могли бы говорить и писать в 5 раз экономнее,
но... сколько времени мы бы тогда тратили на
расшифровку сообщения?
В принципе возможно построить совершенно
безызбыточный язык, так называемый оптимальный
код. В нем каждое случайное сочетание букв
означало бы осмысленное слово. Но пользоваться
им было бы невозможно. Как в свое время заметил
один из популяризаторов нашей кибернетики
И.Полетаев, "никакой аптекарь не рискнул бы
выполнить рецепт, написанный типичным врачебным
почерком, если бы ошибка в одной букве меняла
слово «аспирин» на слово «стрихнин»". Да и
жизнь машинисток и наборщиков, телеграфистов и
редакторов была бы сплошным мучением.
Конечно, в одном и том же канале можно встретить
разные по избыточности тексты. Хорошо бы таким
способом сравнить плотность информационного
содержания в текстах разных писателей. Убежден,
что не только теория информации, но и теория
литературы почерпнула бы от таких экспериментов
немало полезного.
Но оставим литературу литературоведам и
перейдем к специальным языкам. Строго говоря,
это, конечно, не языки. Но так называют способы
построения текстов, А подлежащих передаче по
каналу со специфическими свойствами, например, с
высоким уровнем помех. Особенно часто они
используются там, где ошибка в расшифровке
сообщения стоит чересчур дорого. С
этой точки зрения для нас наиболее интересен
язык аэродромных диспетчеров, на котором они
общаются по радио с пилотами взлетающих и
садящихся самолетов. Соответствующие
исследования показали чудовищную избыточность,
языка диспетчеров — до 96 процентов. Только
столь низкая информационная плотность сигнала
позволяет преодолеть высокий уровень помех. И
хорошо, что никому в голову не приходит объявить
96 процентов слов в радиопереговорах лишними,
«мусорными» и наказывать пилотов и диспетчеров
за многословие.
А каковы условия передачи генетической
информации? Она происходит на молекулярном
уровне, а как утверждают биофизики, «молекулярная
машина существует в оглушительном тепловом шуме,
«целесообразные» движения ее деталей происходят
среди теплового беспорядка и являются
статистическим итогом разнонаправленного
«броунирования». Львиная доля мутаций —
изменений структуры наших генетических программ
— определяется именно тепловым шумом, то есть
хаотическим («броуновым», или, как сейчас стали
писать, «брауновым») движением молекул в клетке.
С точки зрения теории информации он полностью
аналогичен шуму в репродукторе приемника (тот
вызывается тепловыми флуктуациями электронов в
цепях усилителя). Так стоит ли удивляться, что
избыточность наших генетических программ столь
велика? И имеем ли мы право называть
избыточную ДНК эгоистичной и паразитической?
Иное дело — выяснить, каковы механизмы, с помощью
которых избыточность генетического текста
превращается в его помехоустойчивость.
Несомненно, их несколько. На некоторых мы позже
остановимся особо, потому что анализ их приводит
к любопытным и важным выводам. Но прежде надобно
рассмотреть структуру самих генетических
текстов,
С чего начинает исследователь, если ему в руки
попадает закодированный на неизвестном языке
текст? Сначала он определяет, сколько в нем
знаков (символов, букв) и как часто встречается
каждый знак по отдельности и в сочетаниях с
другими. Большой удачей считается на этой стадии
выявить символ, обозначающий пробел между
словами. Но его может и не быть. Древние римляне и
греки, средневековые новгородцы писали без
пробелов. Вообще открытие пробела
было своего рода революцией, чуть ли не вдвое
повысившей скорость считывания информации.
Далее наш дешифровщик будет стараться найти
устойчивые группы, устойчивые сочетания знаков
(слова), которым он будет приписывать какой-либо
смысл. На этой же стадии выявляется тип языка:
имеет ли он флексии, каковы закономерности
изменения начал и окончаний слов и так далее.
Теперь, в эпоху компьютеров, подобные работы
проводятся относительно быстро — при условии,
что исследуемый текст достаточно велик.
Этрусский язык, например, до сих пор не
расшифрован, потому что в распоряжении
исследователей имеются лишь короткие,
неинформативные надгробные надписи.
Казалось бы, этот метод вполне подходит и для
дешифровки текстов на языке ДНК. К сожалению,
перед молекулярными генетиками встали
трудности, неведомые этрускологам.
Еще двадцать лет назад мы практически не умели
читать ДНК-тексты. Было известно лишь, что они
«написаны» 4-буквенным алфавитом (А, Т, Г, Ц) и что
аминокислоты в белках и пробелы между белковыми
«словами» кодируются сочетаниями из этих
четырех букв по три. Даже сейчас, когда прочитаны
уже миллионы этих букв, в распоряжении
дешифровщиков нет ни одного достаточно
представительного куска генетического
сообщения.
И тем не менее о структуре наших программ мы
знаем уже немало. Молекулярным биологам помогло
то, что ДНК — двойная спираль комплементарных
друг другу последовательностей. Меняя
внешние условия, спираль ДНК можно разделить на
две цепочки (денатурировать), можно снова
восстановить двойные спирали (этот процесс
именуется ренатурацией или реассоциацией, или
отжигом). Денатурируя и отжигая ДНК,
предварительно «поломанную» ультразвуком на
куски разной длины, исследователи пришли к
важнейшим выводам о структуре генетического
текста,

Надо сказать, ДНК высших организмов сразу преподнесла сюрприз. Обычно чем разнороднее последовательности в геноме, тем медленнее идет отжиг. Это вполне понятно: хотя в тепловом движении молекул одновременно происходят миллионы столкновений одноцепочечных половинок ДНК, в большой совокупности генов далеко не каждая цепочка сразу находит свою комплементарную половинку. Грубо говоря, чем больше разной обуви в прихожей, тем труднее найти башмак под пару.

Так вот, часть ДНК (до 10 процентов) ренатурировала
крайне быстро — как простая ДНК вирусов. Другая
часть (20—30 процентов) отжигалась медленнее, в
зависимости от концентрации — многими часами. И,
наконец, основной массе ДНК (60— 70 процентов) для
восстановления двойной спирали требовалось
несколько суток.
Объяснить этот факт можно тем, что в ДНК
эукариотных организмов имеются три переходящие
друг в друга фракции. Первая — это меньшая,
«быстрая» часть генома: высокоповторяющиеся
(до нескольких миллионов раз) последовательности.
Именно потому, что они представлены сотнями
тысяч и миллионами копий, их комплементарные
половины быстро находят друг друга при отжиге.
Обычно они состоят из коротких единиц, следующих
друг за другом, как вагоны в поезде. Белков они не
кодируют, и что они делают в геноме — неизвестно.
Высказывались предположения, что именно
они ограничивают скрещивание между особями,
принадлежащими к разным видам, однако доказать
это пока не удалось. Любопытно, что создатель
теории «эгоистичной» ДНК У. Дулиттл не считает их
«эгоистами». По его мнению, это «невежественная»
ДНК, то есть такая, которая выполняет пока
неясную нам функцию только своим наличием,
независимо от содержания.
Вторая фракция, составляющая 20 — 30 процентов ДНК,— среднеповторяющиеся последовательности. Число их копий в геноме колеблется от десятков тысяч до сотен тысяч. Между этой фракцией и предыдущей нет резкой границы: например, AluI — типичная средняя последовательность — представлен в наших геномах 300000 и более копий. На мой взгляд, это самый интересный класс ДНК, позволяющий строить практически неограниченное число гипотез. Именно средние последовательности, во всяком случае, значительную часть их, «обвиняют в эгоизме». Наконец, самая большая часть ДНК, занимающая до 70 процентов, — уникальные последовательности. Судя по названию, каждая из них представлена в гаплоидном геноме только один раз, во всяком случае, не более десяти. Им, конечно, труднее всего найти при отжиге комплементарную пару. С другой стороны, к этому классу относится большинство структурных генов, кодирующих белки.
Но уникальных последовательностей в геномах
высших организмов в 10 —100 раз больше, чем надо ей
для записи информации о всевозможных белках. Что
же делают остальные? Часть их удается
«пристроить» в качестве так называемых
спейсеров-разделителей, разобщающих структурные
гены, но спейсерами бывают и средние повторы.
«Эгоистичными» уникальные структуры тоже
назвать нельзя: согласно этой теории
гены-«эгоисты» защищены от вырезания из хромосом
и сохраняют свой состав. Поэтому к большей части
уникальных обычно применяют термин «мусорная» и
«мертвая», или иногда «умирающая» ДНК. Но и это
трудно принять, и вот почему. У ядерных
организмов и архебактерий структурные гены
имеют сложное строение. Куски ДНК, кодирующие
белки (экзоны), перемежаются
последовательностями, не кодирующими ничего (интронами). При созревании
информационной РНК интроны из цепочки удаляются,
а экзоны сшиваются в зрелую РНК, на которой может
синтезироваться белок.
Поскольку интроны белка не кодируют, их дружно
объявили ненужными частями гена. Но в уникальных
последовательностях часто встречаются точные
копии структурных генов, которые не содержат
интронов. И они неактивны: на них не идет синтез
РНК, белков они не вырабатывают, их даже назвали
лжегенами (псевдогенами). Что же, ген
теряет активность, если из него вырезать
ненужные части? Тогда какие же они ненужные?...
Нет, определенно уникальные последовательности
в категорию «мусорной» ДНК записываться не
хотят. Но, может быть, в эту категорию следует
отнести псевдогены? Может быть, но только
отчасти: у каких-то видов один и тот же ген
неактивен, у других обретает интроны и вновь
нарабатывает белок. Так что же такое псевдогены
— свалка мусора или запас на будущее, так
сказать, «гены а творческом отпуске»?.
Есть и более странные факты. Но поскольку в
сложной этой ситуации ясности нет, давайте
воздержимся от преждеврменных суждений.
А пока посмотрим, не поможет ли нам, хотя бы в
построении гипотез, аналогия с лингвистическими
текстами.
Еще 10 лет назад в статьях по структуре генома
были модными графики распределения
последовательностей по скорости отжига,
реассоциации. Эти так называемые кривые
кинетики реассоциации сыграли свою роль в
науке, да и сейчас часто используются. Вспомнил я
о них вот по какой причине.
Любой человеческий язык несколько условно можно
трактовать как состоящий из двух категорий слов
(или частей слов). Первая категория — слова, за
которыми стоят какие-то объективные реалии. Это
корни существительных, прилагательных и
глаголов.
Вторая категория — флексии, предлоги, приставки,
артикли, окончания — то, что придает смысл
корням, но без них само смысла не имеет.С другой
стороны, и один корень без соответствующих
«добавок» тоже становится невразумительным.
Например, что значит английское слово trike? Не
спешите с ответом. The strike — забастовка
(существительное). A to strike — бастовать (глагол).
Отдельно же взятый артикль the ни о чем не говорит,
как и частица to.
А что если в генетических текстах структурные
гены выполняют функцию слов первой категории
(ведь за ними стоят реалии — аминокислотные
тексты белков), а повторы и некодирующие белков
уникальные последовательности играют роль слов
второй категории? Тогда станет ясно,что они столь
же необходимы в ДНК-тексте, как и структурные
гены. Попробуйте в разговоре и письме
обойтись одними корнями.
Такие соображения заставили меня лет 10 назад
проделать следующую операцию, Я взял английский
текст (первую главу из общеизвестной книги Дж.
Джерома «Трое в одной лодке») и на досуге выписал
из нее все слова, определив частоту их
встречаемости. А затем построил график,
аналогичный кривой кинетики реассоциации ДНК.
На нем четко выделились высокоповторяющиеся последовательности (the, a, an, to), средние повторы (in, on, into, ing) и, наконец, уникальные, куда попал и Монморенси — ведь кличка знаменитого фокстерьера встречается в первой главе только один раз.
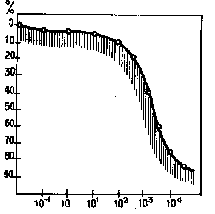
Эти два графика наглядно иллюстрируют аналогию в распределении частоты встречаемости одинаковых участков ДНК в геноме и вспомогательных слов (или их частей) в языке. На левом графике — кривая скорости восстановления (реассоциации) двойных спиралей ДНК из предварительно разделенных одноцепочных половинок. По ней можно судить о процентном составе генома: те структуры, что повторяются часто, занимают в нем небольшую долю. С ростом количества копий генов частота их встречаемости (данные по оси абсцисс) снижается, но процентное содержание в геноме увеличивается. В основном же он состоит из уникальных последовательностей.
Та же картина и на правом графике, где представлены результаты анализа английского текста 1-й главы книги Дж. Джерома «Трое в одной лодке»; четко выделяются группы слов (или их частей), которые также с разной частотой встречаются в тексте (высокие повторы, средние и уникальные) и в соответствии с этим занимают тот или иной его объем.
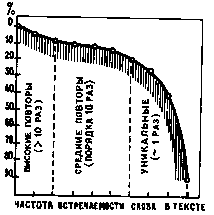
Почему я взял англоязычный текст? С ним легче работать, легче отстраниться. Сейчас я думаю, что русскоязычный дал бы еще более четкую картину — за счет флексий. Человек, владеющий персональным компьютером, был бы способен и на анализ более протяженных и сложных текстов, и аналогия выступила бы еще нагляднее.
Повторяю, аналогия не доказательство, а лишь повод для выдвижения гипотезы (или спекуляции, если хотите). Структурный ген, кодирующий белок, — это только корень слова. Он обретает смысл лишь при взаимодействии с другими последовательностями, роль которых аналогична функции вспомогательных слов в языке. Вирусы и отчасти бактерии практически не имеют повторов в своих простых геномах. Их «язык» напоминает, если хотите, тот язык, на котором объяснялся Тарзан в некогда популярных фильмах, но закодировать на нем достаточно большой объем информации о построении сложного фенотипа невозможно.
Опираясь на этот нехитрый эксперимент, я мог
уже целеустремленно искать в литературе
сведения о функциональной роли повторяющихся
последовательностей и тех механизмах, которые
обеспечивают помехоустойчивость генетических
сообщений. Причем если до сих пор мы говорили о
статике, о структуре генетических текстов, то
ведь не менее интересно посмотреть их в динамике,
в эволюции, начиная с момента происхождения
жизни.
Я вовсе не считаю все последовательности ДНК
функционально значимыми. Подобно тому как все
организмы имеют так называемые рудиментарные
органы, ныне бесполезные, но свидетельствующие
об их истории, так и их геномы могут содержать
реликтовые последовательности, гены-рудименты,
не играющие сейчас никакой роли или очень мало
значимые. Все дело в том, что будь ДНК
действительно мусорной или эгоистической, то не
только 96, но и 30 ее процентов в процессе эволюции
в геноме не удержались бы. А тут
держатся!